- Published on
CockroachDB Distributed Transactions - A Fascinating Interplay of HLC and MVCC
- Authors

- Name
- Bryce Yu
- @earayu
概述
计算机科学一直是一门关于trade-off的科学。在数据库领域,事务的隔离级别便是trade-off的直接体现:隔离级别越高,事务的隔离性越好,但是性能也越差。为了在提高性能的同时保证隔离性,计算机科学家们想出了各种方法,但其中最引人注目的莫过于MVCC了,它使得只读事务与读写事务之间不会互相干扰,能够有效地提高事务的并发度。 但是自从分布式数据库出现后,分布式事务引入了额外的复杂性。首先分布式事务需要保证原子性,如何保证事务原子性的同时不丢失可用性和性能?其次分布式节点之间的“时间”不一致,MVCC的正确性强依赖于“时间”的正确性,现在又如何在分布式的情况下实现MVCC语义呢?当然,除了上述2个之外,还有很多其他的问题,比如如何在分布式下实现不同的隔离级别语义?如何在分布式下做到可靠持久化?等等.....
HLC
为什么分布式系统需要casuality
“物理时间”在分布式系统中是极为不可靠的。因为不同的分布式节点之间的“物理时间”是无法保持同步的,哪怕同一个节点的“物理时间”也并不是单调递增的,受于时间同步算法的影响(如NTP),“物理时间”有可能回退或快进,简单来说,在分布式系统中“物理时间”不是单调递增的。 Lamport发明的“逻辑时钟”虽然可以保证单调递增,但它实际上只是一个计数器,无法被当成“真实的时间”使用。 为什么时间的单调递增那么重要?因为我们需要记录事件的因果关系。举个简单的例子,下图是一个replicated-state-machine:
- Client A对Node1写入x=1,然后Node1将值复制给Node2和Node3。当Node3接受到x=1的请求后,Client A收到了成功返回,此时通知Client B进行下一步。
- Client B对Node3执行x+=1,然后Node3将值复制给Node1和Node2。
- Node2此时收到2个同步请求,(x=1, ts=42.004)和(x=2,ts=42.003)。客观来看,x最终的值应该是2,但x=1的请求的时间戳更大,违反了因果关系。本质的原因是在分布式系统中,物理时间无法保证因果关系。
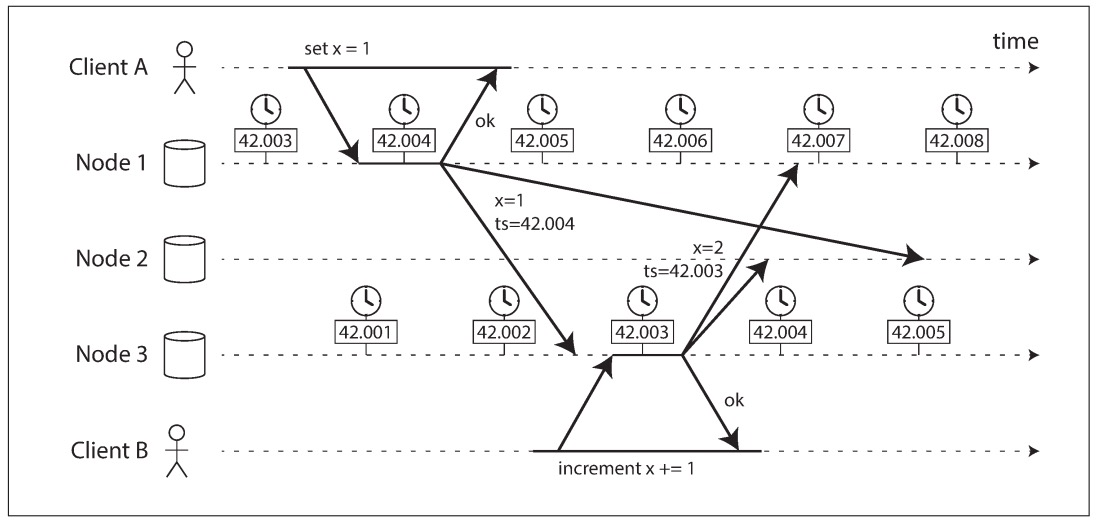
HLC的特点和缺点
言归正传,HLC(Hybrid Logical Clock 混合逻辑时钟)结合了物理时间和逻辑时钟的优点,提供了下面3个特性:
- 如果a happened-before b, 则hlc(a) < hlc(b)。不过反之不成立
- HLC的时间戳占用的bit数不变
- 误差有上届。(其实就是NTP的最大误差,也就是所有机器的物理时间的最大误差)
HLC本质上来说还是一个逻辑时钟,所以它只能提供partial ordering,而不能提供total ordering。所以2个节点中发生的独立事件a和b,如果他们的timestamp在误差的上届范围内,是无法排序的。这个缺陷最终也导致了CockRoachDB没有实现Strict Serializability。
MVCC
“标准”的并发冲突协议太严格了!
在An Empirical Evaluation of In-Memory Multi-Version Concurrency Control论文中提到了多种非常具体的并发控制协议,但它们(至少前3者)都太“严格”了,以至于很多可以允许发生的情况都会被禁止。当我们将论文中的并发控制算法和实际数据库的MVCC实现比较的时候就会发现,现实场景总是跟论文有点神似,但又不一样。 比如CockRoachDB使用的是MVTO-style的多版本并发控制协议,但它在处理并发冲突的时候,不像论文中的MVTO一样频繁abort,而是会尝试修改timestamp后重试。 又如Percolator,当它的读事务遇到并发冲突的时候会先尝试自旋等待,超过了一定时间限制后,它会尝试抢占写事务的锁,强行执行读事务。 所以,实际上对于并发冲突来说,我们能使用的策略很多,包括但不限于:abort当前事务、抢占锁并执行当前事务、自旋等待、修改时间戳后重试...... 那问题的边界在哪里? 我觉得应该着眼于的是MVCC和事务ACID的约束条件:
- 保证一定能读取到commit的数据。后面记作(No Stale Read)
- 保证一定不能读取到未commit的数据。
- 保证写写冲突,只有一个能提交成功
多版本并发会遇到哪些问题?
本文概述中提到:“MVCC使得只读事务与读写事务之间不会互相干扰”。这句话其实是不严谨的。MVCC全称是Multi-Version Concurrency Control(多版本并发控制),实际上它保证的是不同物理版本之间的只读事务与读写事务之间不会互相干扰。 约定一下:只读事务接下来称之为读事务R,读事务R的时间戳记为Rts;读写事务接下来称之为写事务W,写事务R的时间戳记为Wts。
读写事务并发时,主要会产生3类的冲突: 读-写冲突:当写事务write一个对象的时候,发现它正在被一个并发读事务read 如果Wts>Rts,不冲突 如果Wts<Rts,W事务可以abort/修改Wts后重试
如果不做控制直接让W事务执行的话,就有可能使得R事务后续读到新增的数据。这样就有可能使得R违反了Read Commited的约束条件。 我们其实可以思考一下:最宽松的情况下,其实W事务甚至都可以抢占R事务的锁(如果R事务还没执行完毕)。然后W事务强行执行成功,R事务在commit的时候abort。
写-读冲突:当读事务read一个对象的时候,发现它正在被一个并发写事务write 如果Wts>Rts,不冲突(如果是MVTO论文中的描述,此时会abort,但实际可以确定要读取的版本已提交且不会再改变) 如果Wts<Rts,R事务可以abort/wait/抢占锁
如果不做控制直接让R事务执行的话,问题其实在于R事务无法确定W最后能否执行成功。W事务有可能会commit,也有可能会abort。 所以R事务可以abort自己、等待W事务的结果、也可以抢占W事务的锁。Percolator中使用的策略就是先等待,再抢占。
写-写冲突:当写事务write一个对象的时候,发现它正在被另一个写事务write 如果W2ts>W1ts,W1已提交,不冲突 如果W2ts>W1ts,W1未提交,则W2可以abort/修改W2ts后retry/抢占锁/wait 如果W2ts<W1ts,W1已提交,则W2可以abort/修改W2ts后retry 如果W2ts<W1ts,W1未提交,则W2可以abort/修改W2ts后retry/占锁(可以试试先wait,如果W1 abort则可以继续,否则退化成前一种情况。但是wait的效率很低,所以是很差的策略,可以不考虑) 以上如果有wait(或修改W2ts后retry)策略,需要引入死锁检测机制
跟前2种情况一样,在保证MVCC和事务约束条件的情况下,我们能采取的策略可以很灵活。限于篇幅,这边不展开讨论了。
CockRoachDB
特别的隔离级别
CockRoachDB提供的隔离级别很有趣。目前CockRoachDB只提供了Serializability隔离级别,但是又没有达到Strict Serializability的标准。 所以跟Strict Serializability的差距在哪里? CockRoachDB的事务的时间戳都是通过HLC获取的,而前文我们提到HLC的一个缺陷:2个节点中发生的独立事件a和b,如果他们的timestamp在误差的上届范围内,是无法排序的。 考虑这样一个场景:
- 只读事务R开始,但还没有提交。事务R:select * from t1
- 写事务W1开始,并提交。事务W1:insert into t1 values ('foo');
- 随后写事务W2开始,并提交。事务W2:insert into t1 values ('bar');
- 事务R读取到的结果:只有'bar'。(从外部来看,W2晚于W1开始,出现这种结果很奇怪)
出现这种场景的原因在于:R和W1、W2都是并发的,而W1和W2在不同的服务器执行,虽然W2晚开始,但是W2的时间戳小于W1的时间戳。W2的时间戳也小于R的时间戳。
理论上可以使用跟spanner一样的策略来达到Strict Serializability(也称之为Linearlizablity或者External Consistency),但NTP同步事件的误差太大,所以这样的性能几乎不能接受。
原子性
本质上CockRoachDB使用的还是2PC。 prepare阶段:当一个写事务write多行数据的时候,这些数据有可能分散在不同的服务器上,但它们都会指向一条被称之为Transactional Record的记录,它表示当前事务。 commit/abort阶段:Transactional Record记录所在的服务器充当了Coordinator的角色,Transactional Record记录本身也是多副本的。当commit/abort的时候,直接修改Transactional Record就行了。 个人认为CockRoachDB的分布式原子性实现的思路还是很不错的,它实际上把“atomic commit”问题转化成了“consensus”问题。 跟Percolator的区别在于:Percolator使用client作为coordinator,所以coordinator不可恢复。事务有一个超时时间,如果事务挂了,则在它超时之前是会block其他事务的。
并发控制协议
需要处理的并发冲突还是可以分成MVCC的3类: 读-写冲突:
An Empirical Evaluation of In-Memory Multi-Version Concurrency Control论文中提到MVTO协议拥有一个read-ts字段,它记录了某个物理版本的最大读事务的时间戳。后续如果有写事务的时间戳小于read-ts,则写事务直接abort。
还记得MVCC那一节也说到了读写冲突吗?前文写道:“如果Wts<Rts,W事务可以abort/修改Wts后重试”。 那显然,“标准MVTO”使用的策略就是不管三七二十一地abort。 但CockRoachDB使用的策略是:修改Wts后重试。具体实现是这样的:每个数据库节点中记录了一个timestamp cache(相当于read-ts),如果当前写事务W发现timestamp cache中存在一个时间戳t2大于它的时间戳t1,则它会将自己的时间戳t1推迟到刚好大于t2,然后尝试重新执行事务。
写-读冲突: 前文提到:“如果Wts>Rts,不冲突(如果是MVTO论文中的描述,此时会abort,但实际可以确定要读取的版本已提交且不会再改变)”。CockRoachDB的策略就是当作不冲突,直接忽略W事务。 前文提到:“如果Wts<Rts,R事务可以abort/wait/抢占锁”。CockRoachDB的策略就是自旋等待。
写-写冲突: 如果W2id>W1id,CockRoachDB的策略就是自旋等待。(跟写读冲突一样) 如果W2id<W1id,CockRoachDB的策略就是将自己的时间戳推迟到刚好大于W1,然后尝试重新执行事务。(跟读写冲突一样)
HLC误差的副作用
NTP可以将节点间的时间误差(后记作Read Uncertainty Interval)锁定到一个范围内,这个范围也就是HLC的误差上届,后面记为:max_offset。当我们在某一个节点上获取hlc(a),此刻在任意其他节点获取到的hlc(b)的范围是[hlc(a)-max_offset, hlc(a)+max_offset]。
让我们思考一下,CockRoachDB如何保证Read Commited? 举个例子,假设当前max_offset=5:
- 事务W在节点A上执行事务,写入一条数据D,时间戳t1=100
- 事务R在节点B上执行事务,读取同一条数据D,时间戳t2=98
当事务R执行的时候扫描到数据D,发现有一个版本的时间戳是100,而它此时的时间戳是98时,它实际上无法确定这个版本是在它之前,还是它之后提交的。当然,如果t1的时间戳>103,则t1肯定是在R之后执行的。而如果t1的时间戳在[93,98]范围内,则它还是有可能是在R之后执行的。
CockRoachDB的策略很简单,只要t1在(-INF, t2+max_offset]范围内,都视为t1先于t2。然后将t2的时间戳推迟到大于t1,然后尝试重新执行事务(跟前文一样)。 这样可行的基本原理在于:
- 漏读数据是决不允许的,因为可能违反Read Commited约束。
- 多读数据是可以的,因为并发事务可以任意排序,并且将时间戳往后推和发送事务请求时网络delay,也没有本质区别。
事务性能优化
简单提一下,CockRoachDB使用了2个策略优化分布式事务的性能,这也许就是它能默认把Serializable作为唯一隔离级别的底气吧。 **write pipeline:**同一个事务中对多个key的读写可以并发,有依赖关系的key的读写,则当然只能串行执行了。 **Parallel Commits:**之前提到事务commit/abort的时候修改的是Transactional Record的状态,但修改它的状态需要一次分布式共识的RT。实际上,如果所有的key都读写完毕(分布式共识也多数同步完成),则哪怕Transactional Record的状态没有修改,这时候也可以立即返回给客户端了。因为数据铁定不会丢了,后续通过可以判断各种状态,来修复Transactional Record的状态。
总结&后记
CockRoachDB给我的感觉是很多设计思路都相当激进,但有一种不撞南墙不回头的感觉(好的方面)。所以它整个事务层的设计我都觉得很靓眼,也惊叹于他们只支持Serializable隔离级别的魄力。 本文起始于我看完HLC论文后总觉得云里雾里,感觉无法跟实际使用结合起来。然后开了一个个坑:MVCC、SSI、CockRoachDB。好在全都硬啃了一下,虽然谈不上有深入的理解,但至少知道了一些基本原理。特别是在MVCC那边,我发现原来分布式事务的并发控制策略是可以那么灵活的。之前看Percolator的分布式事务时只是被动接受它的设定,现在明白了原来可以有不同的设计策略。 总之,分布式事务还是很有意思的。不过关于分布式事务,本文还有很多方面没有聊到。比如更多的分布式时间相关的东西(TSO、原子钟)、分布式共识等等:)。
参考资料
- Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases
- An Empirical Evaluation of In-Memory Multi-Version Concurrency Control
- CockroachDB: The Resilient Geo-Distributed SQL Database
- Serializable Snapshot Isolation in PostgreSQL
- CockRoach Transaction Layer Docs
- Living Without Atomic Clocks
- CockroachDB’s Consistency Model
- Distributed Systems - An Algorithmic Approach - Chapter 6